아래 내용은 NVIDIA Isaac GR00T 생태계 기반의 “합성 데이터 중심(synthetic-data-first)” 휴머노이드 AI 학습 파이프라인 전체를 담고 있습니다. 사전 학습용으로, 전체 그림 → 단계별 상세 → 용어 정리 순으로 풀어드리겠습니다.
<프로젝트의 본질>
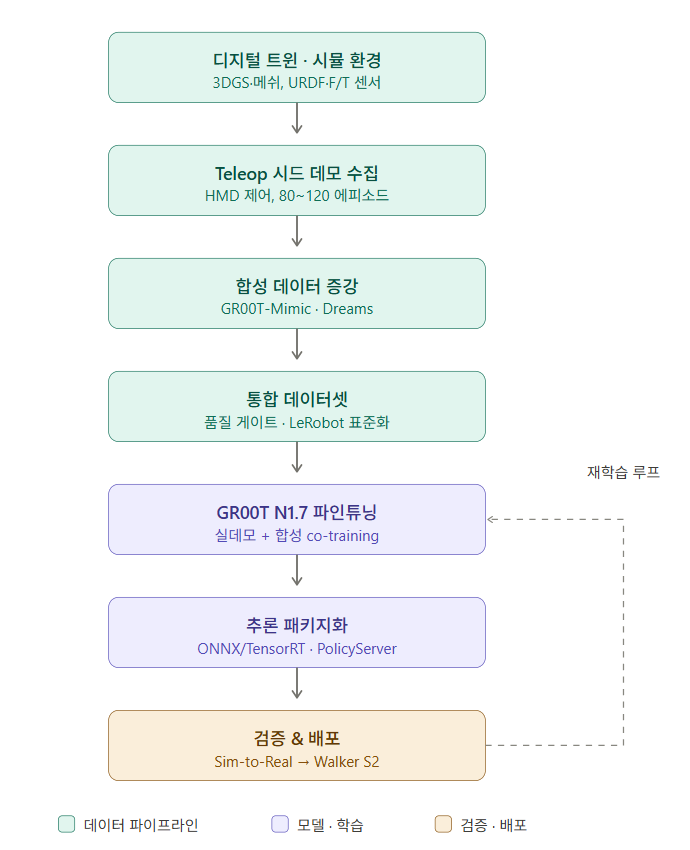
사람이 하던 작업을 휴머노이드가 자율 수행하도록, NVIDIA GR00T라는 ‘VLA 모델’을 학습시키는 프로젝트입니다. 여기서 가장 중요한 패러다임은 “현실에서 데이터를 많이 모으지 않는다”는 점입니다. 현장 데이터(텔레오퍼레이션) 수백 건을 사람이 일일이 만드는 대신, 디지털 트윈(가상 시험실)을 정밀하게 만들고 → 그 안에서 합성 데이터를 대량 생성 → 그걸로 AI를 학습시키는 방식입니다.
1단계 — 디지털 트윈과 환경 구축
이 프로젝트에서 가장 독특한 기술 선택이 여기 있습니다. 현장을 두 가지 방식으로 동시에 복제합니다.
- 3DGS(3D Gaussian Splatting) 는 “시각” 담당입니다. 현장을 3D 스캔한 데이터를 수백만 개의 반투명 색 점(가우시안)으로 표현해, 사진처럼 사실적인 화면을 실시간으로 렌더링합니다. 로봇 카메라가 “진짜 시험실처럼 보이는” 영상을 보게 하려는 목적입니다.
- 메쉬(Mesh) 는 “물리·충돌” 담당입니다. 3DGS 점구름은 예쁘지만 물리 엔진이 “이 물체에 부딪혔다/잡았다”를 계산하지 못합니다. 그래서 같은 공간을 다각형 메쉬로도 만들어 충돌·중력·접촉을 계산합니다.
이 둘을 하나의 씬에 합친 것이 하이브리드 디지털 트윈입니다(시각은 3DGS, 물리는 메쉬). 여기에 시험기 본체·여닫는 도어(Articulated, 즉 관절로 움직이는 부품)·시편 매거진을 3D 자산으로 모델링해 넣고, 휴머노이드의 URDF·관절한계·F/T 센서·로봇 시점 카메라까지 가상으로 정합시키면 “가상 시험실 + 가상 로봇”이 완성됩니다.
마지막 핵심 개념이 도메인 랜덤화(Domain Randomization) 와 Real-to-Sim 정합성입니다. 가상에서만 학습한 AI는 현실에 가면 조명·재질이 미묘하게 달라 실패하는데(이를 sim-to-real gap이라 합니다), 이를 막기 위해 학습 중 조명·재질·물리 값을 무작위로 마구 흔들어줍니다. 다양한 변형을 다 본 AI는 현실의 변형에도 강해집니다. 동시에 실측값과 비교해 가상이 현실과 얼마나 맞는지 측정·보정하는 작업이 Real-to-Sim 정합성입니다.
2단계 — 데이터 수집 (실데모)
Teleop(텔레오퍼레이션, 원격조종) 는 사람이 직접 로봇을 조종해 “정답 시범”을 만드는 과정입니다. 여기서는 HMD(VR 헤드셋) 를 쓰는 점이 특징입니다. 사람이 VR을 쓰고 손을 움직이면 가상 로봇이 따라 움직이며 작업을 시연하고, 그 궤적이 학습 데이터가 됩니다. 더 작고 저렴한 휴머노이드인 Unitree G1으로 파이프라인을 먼저 검증한 뒤 본 로봇으로 옮긴다는 의미입니다.
수집 단위는 에피소드(episode), 작업 1회분 입니다. 계획 수집은 휴머노이드 학습치고는 매우 적은 양인데, 이것이 가능한 이유가 바로 다음 단계의 합성 데이터 증강입니다. 별도로 진행되는 “고품질 영상 렌더링” 트랙은, 저품질 환경에서 빠르게 모은 궤적을 나중에 고품질 가상 환경에서 다시 재생·렌더링해 학습용 영상의 품질을 끌어올리는 작업입니다.
3단계 — 데이터 처리 (합성 증강이 핵심)
소수의 실데모를 수십~수백 배로 불리는 단계입니다. NVIDIA Isaac GR00T 생태계의 두 엔진을 씁니다.
GR00T-Mimic (Isaac Lab Mimic 기반) — 사람이 시연한 소수 궤적을 받아, 물체 위치·자세·배치를 조금씩 바꿔가며 같은 작업의 변형을 대량 자동 생성합니다(포즈·배치 변이). 거기에 Cosmos Transfer로 조명·환경·재질을 바꾸는 스타일 변환을 입혀 포토리얼한 변형 데이터를 만듭니다. Cosmos Transfer는 시뮬레이터(예: Omniverse)에서 만든 물리 기반 영상에 조명·환경을 바꾸는 다중 제어 스타일 변환을 적용하는 모델입니다. NVIDIA
GR00T-Dreams (DreamGen 파이프라인) — 사전학습된 월드모델로 합성 로봇 데이터를 “꿈처럼” 생성해, 사전학습 데이터에 없던 새로운 동작(verb)까지 일반화시킵니다. 흐름은 ① Cosmos-Predict(현재 2.5 버전)가 미래 영상을 생성 → ② Cosmos-Reason(영상을 추론·이해하는 VLM)이 물리적으로 말이 되는 것만 필터링 → ③ IDM(Inverse Dynamics Model, 역동역학 모델) 이 그 영상에서 로봇이 어떤 동작을 해야 그렇게 되는지 신경망 궤적(neural trajectory)을 역으로 뽑아냅니다. 참고로 Cosmos Predict 2.5는 Text2World·Image2World·Video2World를 한 모델로 통합했고, Cosmos Reason을 텍스트 인코더로 사용합니다(“Cosmos-Predict2″는 이 2.x 계열을 가리킵니다). NVIDIA ResearchHugging Face
생성한 데이터는 그대로 쓰지 않습니다. 합성 데이터 품질 게이트에서 물리적으로 타당한지(예: 손이 물체를 통과하지 않았는지) 검증해 불량을 걸러냅니다. 통과한 데이터는 LeRobot 스키마로 표준화합니다 — EmbodimentTag(어떤 로봇 몸체인지), 액션 공간(관절 명령 형식), observation(관측 입력), 메타데이터를 통일된 포맷으로 정의하는 작업입니다. 마지막으로 실데모 + Mimic + Dreams를 합쳐 버전 관리되는 통합 데이터셋을 빌드합니다.
4단계 — VLA 파인튜닝 (학습의 본체)
VLA(Vision-Language-Action) 모델이 이 프로젝트의 두뇌입니다. Isaac GR00T는 비전·텍스트 트랜스포머로 로봇의 이미지 관측과 텍스트 지시를 인코딩하고, flow matching 트랜스포머로 관측에 조건화된 연속 동작 시퀀스를 생성합니다. 쉽게 말해 “카메라로 본 장면 + ‘동작해라’는 지시”를 입력받아 “관절을 이렇게 움직여라”는 연속 동작을 출력하는 모델입니다. Hugging Face
여기서는 GR00T N1.7을 파인튜닝합니다. GR00T 계열은 NVIDIA의 오픈 휴머노이드 파운데이션 모델로, N1.5가 2025년 5월 Computex에서 첫 업데이트로 공개되었습니다. 제가 확인한 공개 문서상 최신은 N1.5이며, N1.7은 그 이후 버전으로 보입니다(내부/신규 릴리스일 수 있으니 실제 버전 가용성은 NVIDIA NGC에서 확인이 필요합니다). The Robot Report
학습의 두 가지 키워드:
- Co-training(공동 학습): 실데모와 합성 데이터를 섞어 함께 학습시켜, 적은 실데이터의 사실성과 대량 합성데이터의 다양성을 동시에 취합니다.
- Cross-embodiment(크로스 임바디먼트): 서로 다른 로봇 몸체의 데이터를 함께 학습하는 것입니다. G1 Edu(Unitree의 교육용 G1) 데이터를 보조로 넣어 일반화를 돕습니다. GR00T가 본래 여러 로봇에 쓰이는 cross-embodiment 모델이라 가능한 방식입니다.
학습은 H100 GPU 노드에서 돌리며, 재학습 사이클(시뮬·목업·현장 검증 결과를 반영해 정책을 반복 재학습 — 위 그림의 점선 루프)이 별도 태스크로 잡혀 있습니다. 학습이 끝난 정책은 추론 패키지화합니다: PyTorch 모델을 ONNX → TensorRT로 변환해 로봇 위에서 빠르게 돌도록 최적화하고, PolicyServer라는 추론 인터페이스(EOS·ROS2 연동)로 감쌉니다.
5단계 — 검증
학습한 정책이 진짜 쓸 만한지 단계적으로 시험합니다.
- Sim-to-Sim 일반화 평가: 학습 때와 다른 가상 환경에서도 작동하는지 봅니다(과적합 점검). Closed-loop 회귀 벤치는 모델을 실제로 환경 속에서 돌려보며(열린 평가가 아니라 행동→결과→다음 행동의 닫힌 루프) 성능이 이전 버전보다 나빠지지 않았는지 회귀 테스트하는 것입니다.
- 타 로봇 실기 전이 검증 (Sim-to-Real): 가상에서 학습한 정책을 실제 로봇에 올려 end-to-end로 검증하고, 가상-현실 격차(gap)를 측정해 다시 학습에 피드백합니다.
6단계 — 휴머노이드 제어 (실배포)
최종적으로 로봇 제어 시스템을 구성합니다: VLA 정책 서버가 → 카메라 시각 관측을 입력받아 → 액션 청크(action chunk) 를 출력합니다. 액션 청크란 한 스텝씩이 아니라 여러 미래 동작을 한 묶음으로 예측하는 방식으로, 제어가 더 부드럽고 안정적입니다. 마지막 모델 경량화는 무거운 모델을 휴머노이드의 온보드 컴퓨터(Jetson Orin)에서 실시간 구동되도록 줄이는 작업입니다.
다음 편에는 각 단계별 기술적 접근방법을 구체적으로 살펴보도록 하겠습니다.